Vector databases are revolutionizing how organizations store, retrieve, and analyze data by utilizing mathematical representations known as vectors, enabling sophisticated AI applications to operate more efficiently.
In traditional databases, data is typically stored in a structured format such as tables, which makes it easy to manage and query specific information like names, addresses, and product details. However, these databases struggle with the increasing complexity of modern data. This is where vector databases come into play. Optimized for handling vector data, they represent objects through arrays of numbers that capture latent features and encode similarity. For example, a movie’s vector could encapsulate its themes, mood, imagery, and plot. These vector representations allow AI models to interpret objects based on their underlying semantics, making tasks like similarity searches and ranking far more efficient. Vector databases not only store these vectors effectively but also index them for quick retrieval, providing the essential infrastructure for AI-driven applications.
What Are Embeddings? #
Embeddings are crucial for transforming high-dimensional data into lower-dimensional vectors, retaining most of the original information. This process is integral for various machine learning tasks.
– Word2Vec: Encodes words based on surrounding context patterns. Words with similar meanings have similar vectors.
– Doc2Vec: Extends Word2Vec by embedding entire documents. Documents about similar topics cluster together.
– Image Embeddings: Encode images based on visual features like objects, scenes, and textures detected by a neural net.
– Graph Embeddings: Represent nodes in a graph based on connection patterns and node attributes.
Understanding embeddings sets the stage for comprehending how vector databases operate and why they are so powerful in AI applications.
How Do Vector Databases Work? #
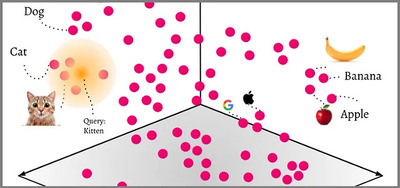
Image source: devgenius blog
As data complexity increases, traditional databases often falter in managing and retrieving it efficiently. Vector databases are tailored to handle high-dimensional data by representing it as vectors.
– Ingestion and Indexing: Efficiently stores numerical feature vectors.
– Advanced Indexing Techniques: Uses hierarchical navigable small-world graphs for fast nearest-neighbor lookups.
– Similarity Calculations: Matches query vectors with indexed vectors for semantic matching.
– Dimensionality Reduction: Compresses vectors for a smaller storage footprint while maintaining accuracy.
– GPU Acceleration: Uses GPUs for parallel vector computations during queries.
These capabilities enable vector databases to perform complex operations swiftly, making them indispensable for modern AI tasks. Next, we will delve into building intelligent vector databases.
Building Intelligent Vector Databases #
Intelligent vector databases enhance data retrieval through advanced algorithms and scalable infrastructure. They add several key capabilities to meet modern data needs.
– Vector Indexing: Supports ultra-efficient querying of vector fields for similarity search.
– Dimensionality Reduction: Reduces vector dimensions while preserving essential information.
– GPU Acceleration: Leverages GPUs for fast parallel processing.
– Cloud Integration: Scales across clusters and integrates with cloud services seamlessly.
Leading options like Pinecone, Milvus, and Weaviate offer robust platforms to industrialize AI. In the next section, we’ll explore how these technologies drive business value.
Driving Business Value with Vector Databases and Embeddings #
Vector databases and embeddings can significantly enhance business operations by enabling more sophisticated AI applications. Here are some key areas where they add value:
– Better Recommendations: Use vector similarity for improved product/content recommendations.
– Improved Search: Semantic vector search better understands user intent compared to keyword searches.
– Rapid Document Insights: Efficiently embed and query large document collections for analysis.
– Reduced Fraud: Detect fraudulent patterns in graphs of activities and relationships.
– Predictive Maintenance: Embed sensor data to identify early signs of equipment failures.
By operationalizing vectors and embeddings, companies can infuse products and processes with the true power of AI. Next, let’s look at a practical Python example to see these concepts in action.
The Future of Vector AI #
As AI adoption accelerates, purpose-built vector data platforms will become critical components of enterprise data infrastructure. Combining the right database technologies with advanced embedding techniques will yield deeper insights and performance improvements. Companies that master the storage, organization, and querying of vector data will gain a competitive edge, paving the way for an AI-first future.
Vector databases could very well be the next big thing in data management. Here’s a quick guide to understanding the Use Cases of Vector Databases. Keep this as a reference!
Why Do We Need Vector Databases? #
- Unstructured Data: Vector databases excel at processing and retrieving unstructured data, a task that’s challenging for traditional relational databases.
- Similarity Searches: These databases allow for similarity searches, helping you find items that are ‘close’ in terms of their data representation or “properties.”
Use Cases for Vector Databases #
- Recommendation Systems: Platforms like Netflix and Amazon use vector databases to suggest similar content to users.
- Document Retrieval: These databases can find documents that are similar or related to a given document.
- Image Search: Vector databases are also used in image search systems to find images similar to a given one.
Vector Database Options #
Here is a comparison table of the popular vector databases:
| Database | Backend / Search Technique | Programming Language Support | Use Cases |
|---|---|---|---|
| Pinecone | Approximate Nearest Neighbor (ANN) search | Python, Java, Go, Node.js | Real-time search, recommendations |
| Weaviate | Hierarchical Navigable Small World (HNSW) | Python, Go, Java, JS/TS | Enterprise search, knowledge graph |
| Milvus | Approximate Nearest Neighbor (ANN) search | Python, Java, Go | Similar items, recommendations |
| Elasticsearch | Lucene | Python, Java | Text search, recommendations |
| Jina AI | Hierarchical Navigable Small World (HNSW) | Python | Video/image search, chatbots |
| Qdrant | Facebook AI Similarity Search (FAISS) | Python | Similarity search, recommendations |
| Chroma | in-memory document-vector store | Python, Javascript | semantic search engines over text data |
The Key Takeaways:
- Pinecone, Weaviate, and Milvus are vector databases optimized for speed and scalability. Pinecone and Milvus focus on real-time recommendations while Weaviate does enterprise search.
- Elasticsearch and Jina AI build on top of Lucene and HNSW respectively. Elasticsearch is best for text search while Jina AI handles multimedia well.
- Qdrant uses the Facebook AI Similarity Search (FAISS) library. It’s easy to use in Python for similarity search and recommendations.
- Most options support Python along with other languages like Java and Go. Pinecone and Weaviate also emphasize ease of use.
Contributed by Gaurav Deshmukh, Bot Nirvana member. Updated by Bot Nirvana staff.